在大四的秋季学期(2021),我上了一门个性化在线学习课(05-432/832 POL),课程导师是Vincent Aleven教授和Jonathan Sewall教授。
做期末项目时,我和队友王欣竹合作制作了一个认知智能教学助手,帮助编程新手通过逐行分析的练习学习递归的概念。我们使用了许多人机交互(HCI)的工具与方法来达成不同的目的:
- 出声思维(think aloud)和理论性认知任务分析(theoretical cognitive task analysis; CTA):细化学习目标与知识构件(knowledge components; KC)1;
- 认知导师创作工具(cognitive tutor authoring tool; CTAT)与规则引擎Nools:制作基于产生式规则(production-rules)的智能教学助手(cognitive tutor);
- 用户测试:迭代改进智能教学助手原型。
新手1 - 英语描述版本 |
新手2 - 英语描述版本 |
新手3 - 伪代码版本 |
新手4 - 代码版本 |
|---|---|---|---|
 |
 |
 |
 |
因为我是CMU一节编程入门课15110的助教,我可以联系到20多名本科生助教与300多名编程新手(15110的学生)来进行认知任务分析和用户测试。
在认知任务分析的出声思维报告中(如上图所示),我们发现了一些新手在递归逐行分析练习中常犯的错误,比如识别输入格式、子问题的输入变量、特定问题情境下的基线条件、递归函数返回的顺序等。基于这些发现,我们改进了理论性认知任务分析的模型与智能教学助手的界面设计。
CTA模型(出声思维测试前) |
CTA模型(出声思维测试后) |
|---|---|
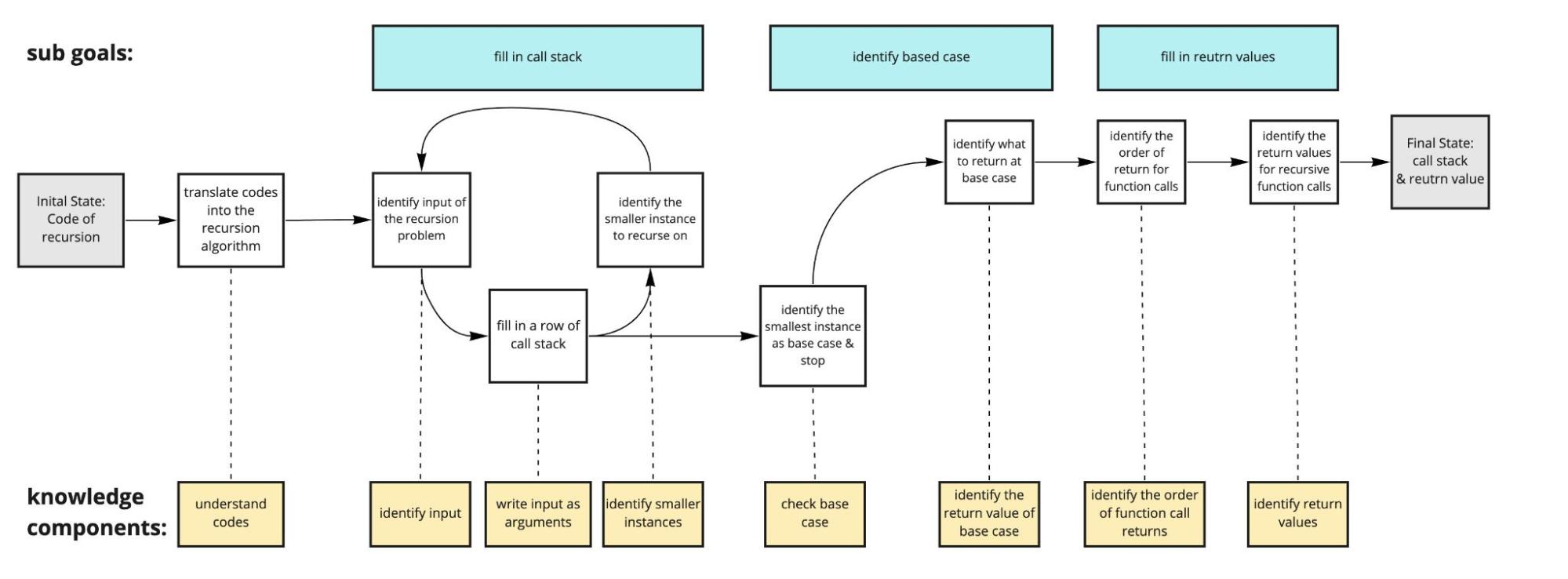 |
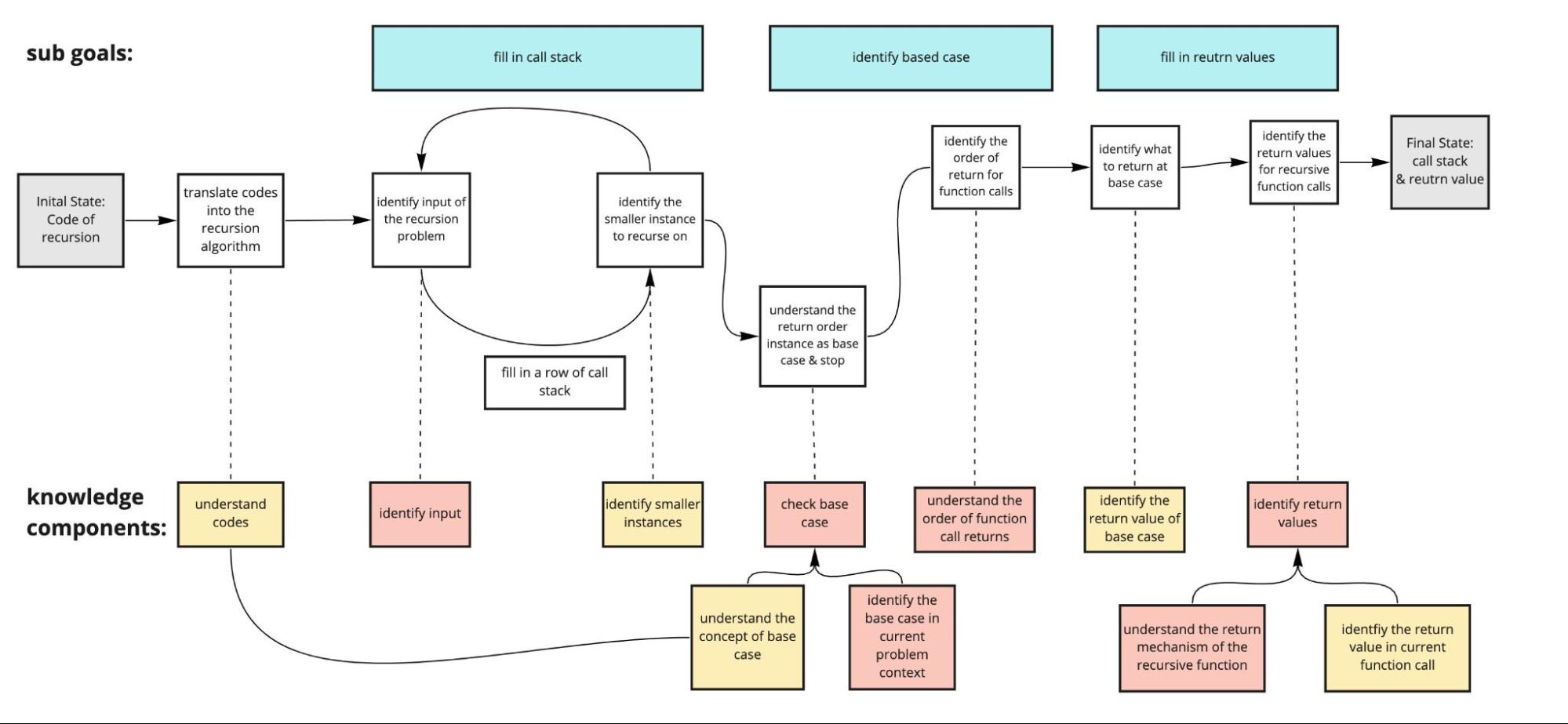 |
制作智能教学助手时,我们设计了一个工作记忆模型(working memory model),其中包含了题、列、格三种主要表现形式。基于CTA与工作记忆的两个模型,我们用Nools撰写了8条产生式规则(详情请见我们的recursionTutor git 项目)。
我们设计了三种使用不同数据结构的递归问题:
recursiveCount- 输入int; 输出intbinarySearch- 输入int list∫ 输出boolevaluate- 输入int list&string list; 输出int
每个问题都有代码与伪代码两种版本(一共3*2 = 6个练习题)。我们假设在逐行分析递归问题中,对于新手而言,代码版本比伪代码版本难,而涉及到更复杂数据结构的evaluate比binarySearch比recursiveCount更难。
智能教学助手界面设计(用户测试前) |
智能教学助手界面设计(用户测试后) |
|---|---|
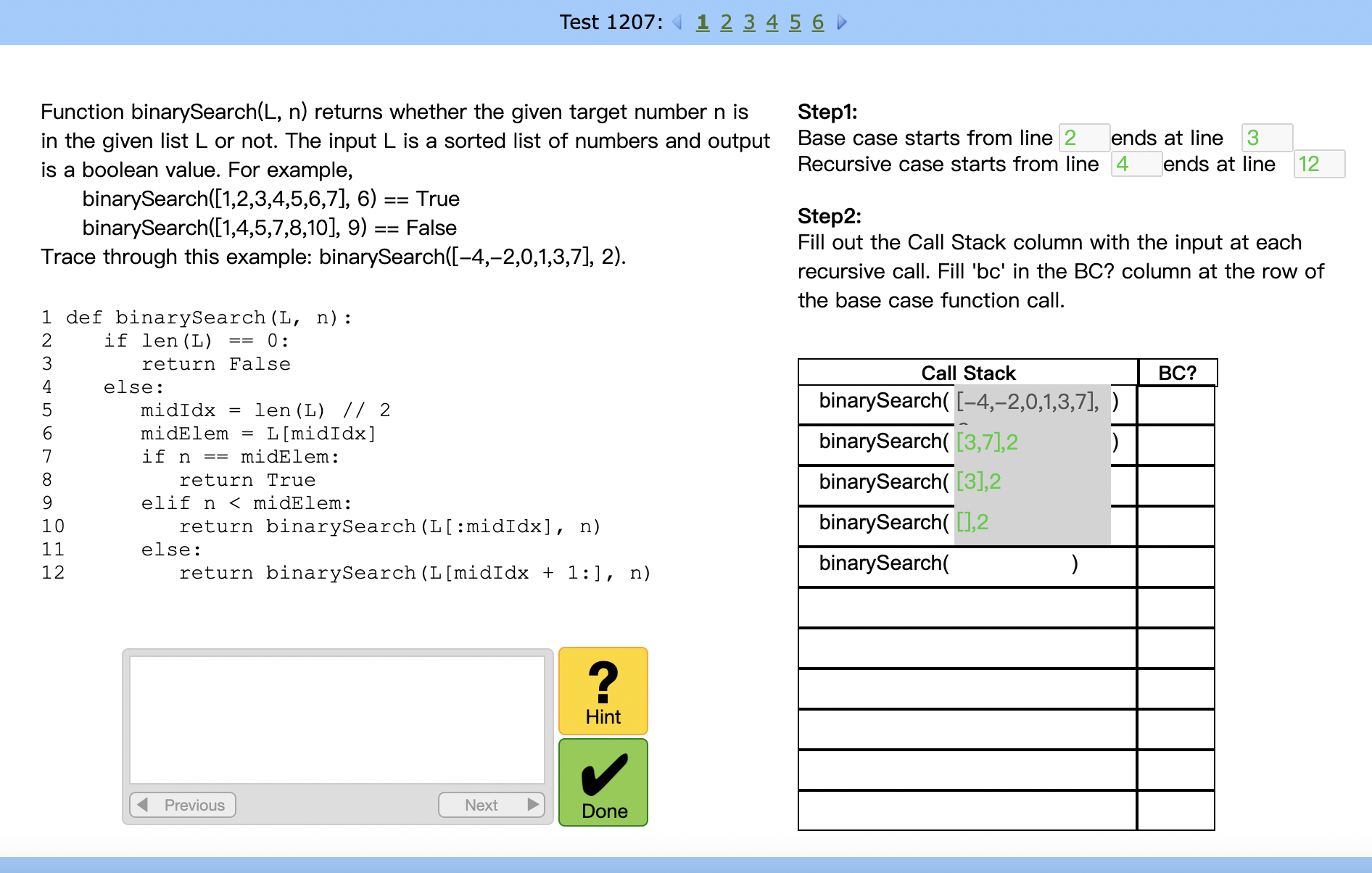 |
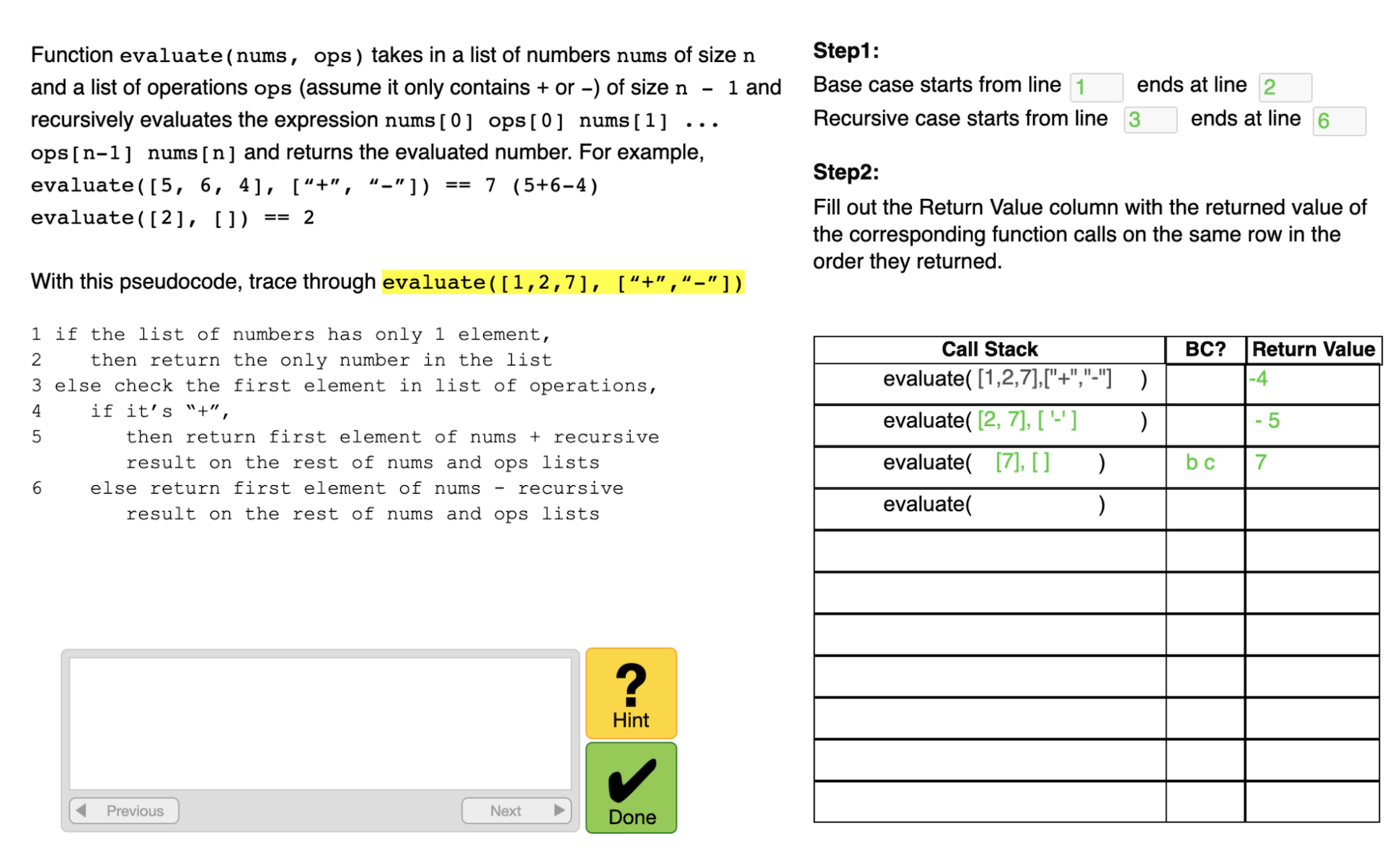 |
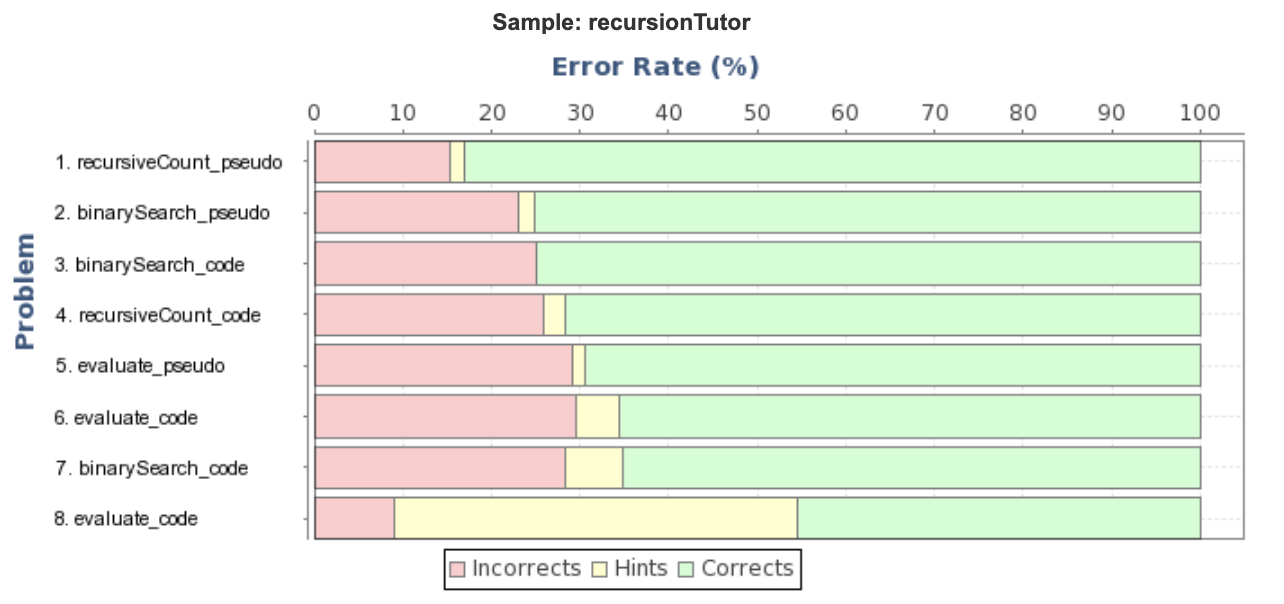
我们邀请了41位用户来测试我们的智能教学助手原型,收集了并分析一些互动日志数据。总体来看,错误率和我们的假设是一致的,即实际代码语法与复杂的数据结构会对编程新手造成额外的困难(反映在我们的CTA模型中对应理解代码与数据结构的KC)。
若想进一步地改进我们的智能教学助手,我们还可以把产生式规则与KC对应起来,把学生的学习进度用技能进度条的形式可视化出来,并在KC层面进行更深入的数据分析、运用诸如学习因子分析(learning factor analysis)之类的工具来完善KC模型2。我们还可以简化生成练习题的流程,用以大量制作递归的问题。
 |
我们的递归智能教学助手收到了学生的许多正面反馈,主要集中于如下的功能特性:
- 动态展示子目标结构
- 逐步反馈如即时报错、提示
- 特定的表格填写顺序(输入从上至下、输出从下至上),强调了递与归的两个阶段
- 调用堆栈、基线、与返回值的三个列表,强调了递归算法中的重要组成部分
同时我们也发现了许多智能助手未能解决的问题,比如识别错误类型并提供更具体、个性化的提示。在KC模型中我们区分了“识别正确的返回值模式”与“在对应行填写正确的返回值”两个知识构件,比如在recursiveCount的问题中,有些学生能够理解返回值应该遵循1…2…3的模式,但填写的时候却会填反了顺序(如新手1、3),或是犯了缺位错误(off-by-one error)。人类助教能够很容易地分辨出学生犯的错误类型,但对于智能助手而言,识别不同种类的错误并提供实时、具体的反馈却要复杂很多。
在这个项目中,我们在实际CS教育环境下应用了课堂上学到的教育理论、设计并测试教育产品,还是很有意思的,也让我对教育科技的优劣势有了更深入的认识。
作为一个课程项目,我们的递归助手能做的十分有限,而且认知导师创作工具(CTAT)的学习曲线也还是很陡峭的(学了大半个学期才能开始用它制作智能教学系统)。不过在可预见的未来,我们可以让这些自适应的科技更加便于教育者使用,让更多学生享受个性化教育。我始终相信教育科技的前途远大、未来光明 :-)
-
Aleven, V., & Koedinger, K. R. (2013). Knowledge component approaches to learner modeling. In R. Sottilare, A. Graesser, X. Hu, & H. Holden (Eds.), Design recommendations for adaptive intelligent tutoring systems (Vol. I, Learner Modeling, pp. 165-182). Orlando, FL: US Army Research Laboratory. ↩
-
Koedinger, K. R., Stamper, J. C., McLaughlin, E. A., & Nixon, T. (2013). Using data-driven discovery of better student models to improve student learning. In H. C. Lane, K. Yacef, J. Mostow, & P. Pavlik (Eds.), Proceedings of the 16th international conference on artificial intelligence in education AIED 2013 (pp. 421-430). Berlin, Heidelberg: Springer. doi:10.1007/978-3-642-39112-5_43 ↩