In my senior year fall (2021), I took Personalized Online Learning (05-432/832 POL) with Dr. Vincent Aleven and Dr. Jonathan Sewall.
I collaborated with Xinzhu Wang to develop a cognitive tutor that helps novice programmers practice recursive code tracing. We used
- think aloud and theoretical cognitive task analysis (CTA) to specify learning goals and knowledge components (KC)1;
- cognitive tutor authoring tool (CTAT) and Nools to build a production-rules-based cognitive tutor;
- user testings to iteratively improve our tutor prototype.
Novice1 - English version |
Novice2 - English version |
Novice3 - Pseudocode version |
Novice4 - Code version |
|---|---|---|---|
 |
 |
 |
 |
Because I am a teaching assistant (TA) of 15110, an introductory programming course at CMU, I can conveniently reach to 20+ TA and 300+ students for CTA & user testings. After think aloud (some notes are shown above), we identified some common errors that novices make in recursive code tracing tasks, such as identifying actual input format, smaller input, base case in a specific problem context, order of return, and etc., which enabled us to update our theoretical CTA model and make design choices accordingly.
CTA model before think aloud |
CTA model after think aloud |
|---|---|
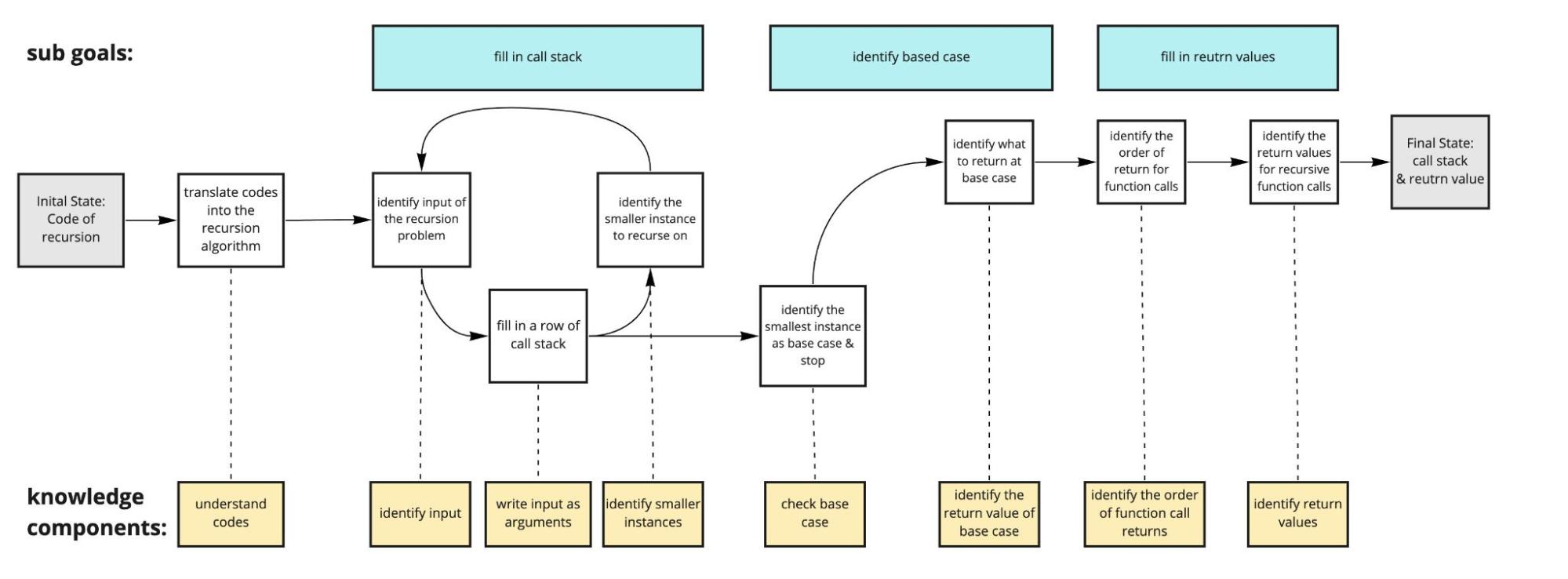 |
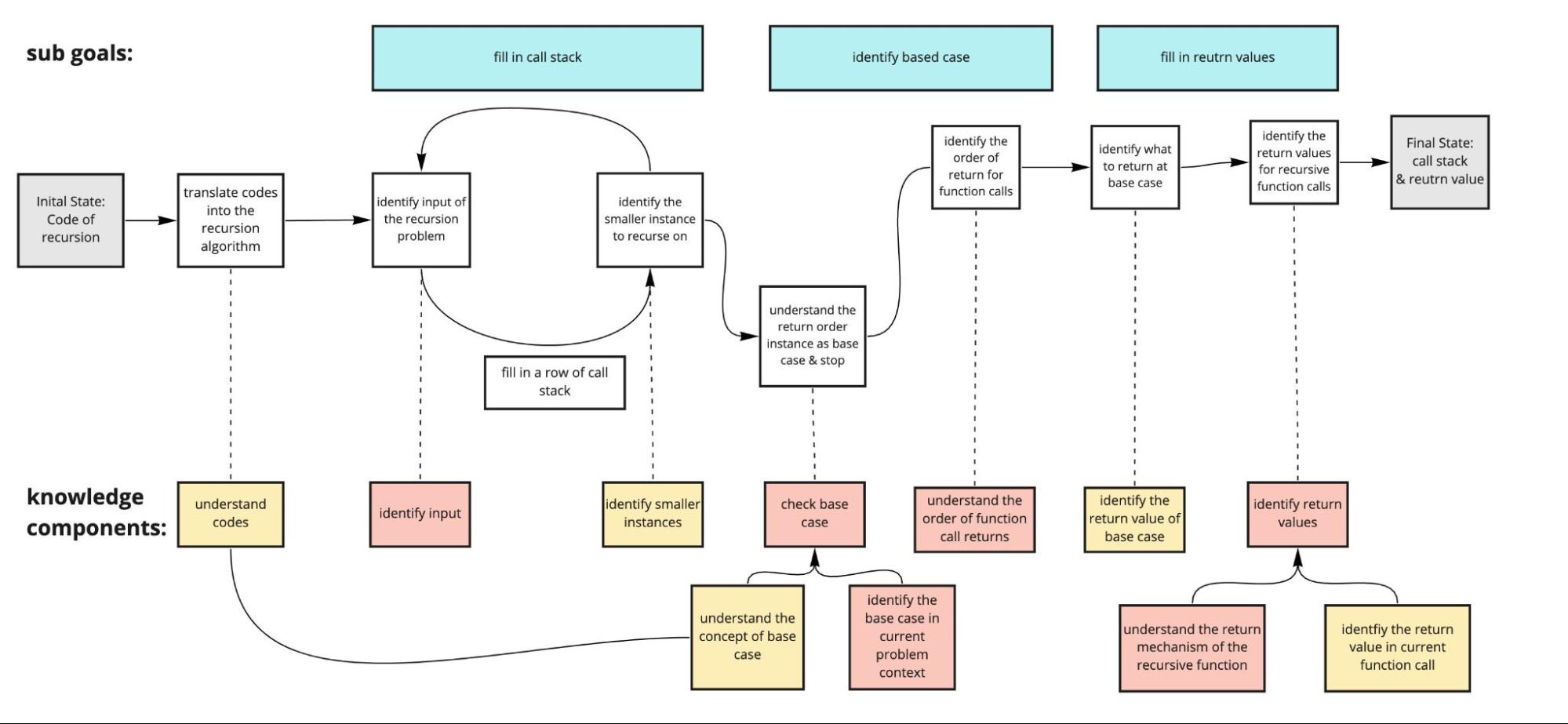 |
For the recursion cognitive tutor itself, we created a working memory model that includes 3 main types: Problem, Column, and Cell. We specified 8 production rules based on our CTA results and working memory diagram. Please refer to our recursionTutor git repo for the actual implementation.
We provided 3 problems with different data types:
recursiveCount- inputint; outputintbinarySearch- inputint listandint; outputboolevaluate- inputint listandstring list; outputint
Each question has a pseudo-code & code version (3*2 = 6 problems in total) to test out students’ understanding of different formats of presentation of recursive algorithm. We hypothesized that understanding the actual code syntax and complex data structures would create additional challenges for novice programmers, so the code versions would be harder than pseudocode, and evaluate >harder> binarySearch >harder> recursiveCount.
Tutor interface before user testing |
Tutor interface after user testing |
|---|---|
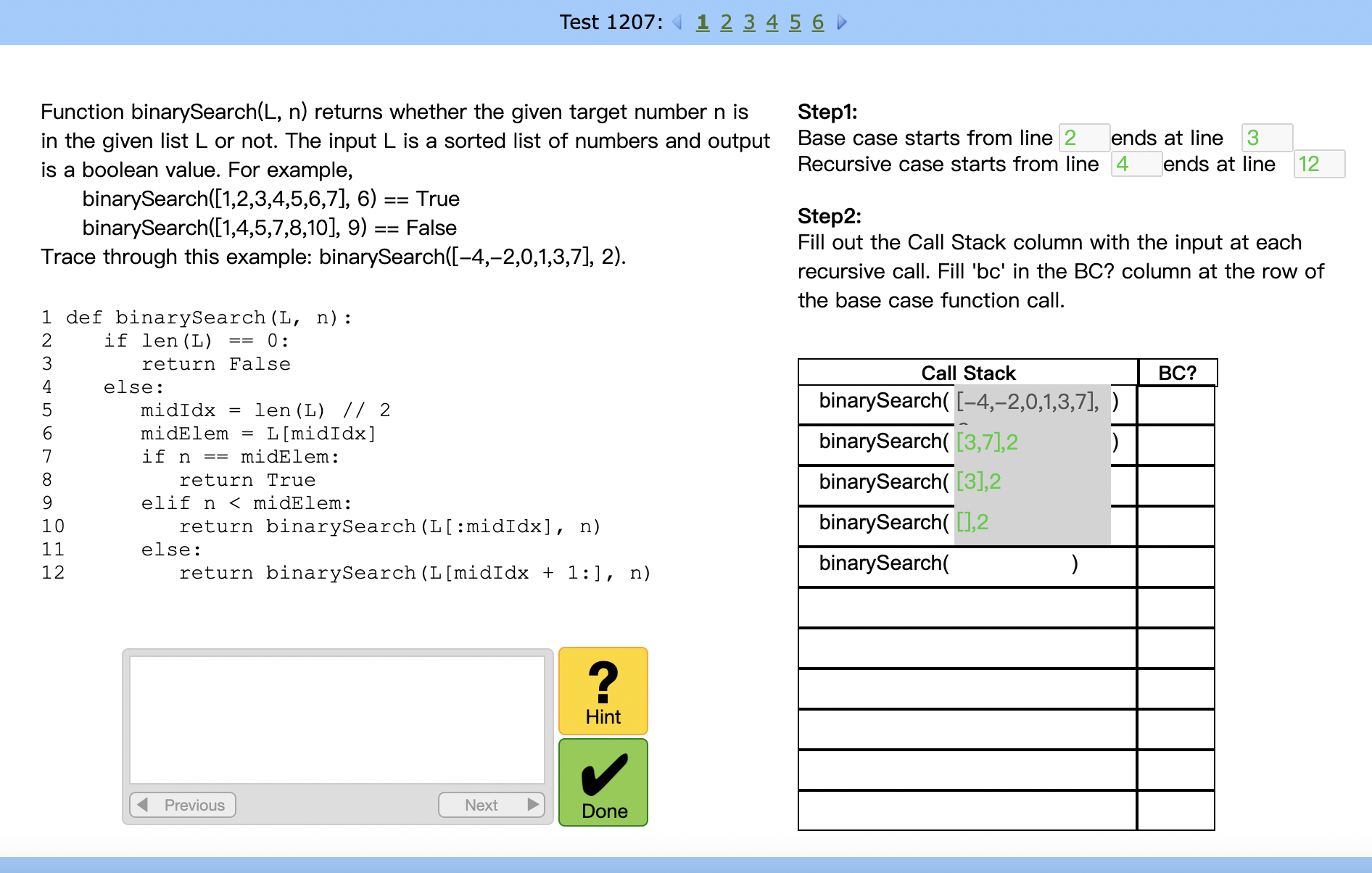 |
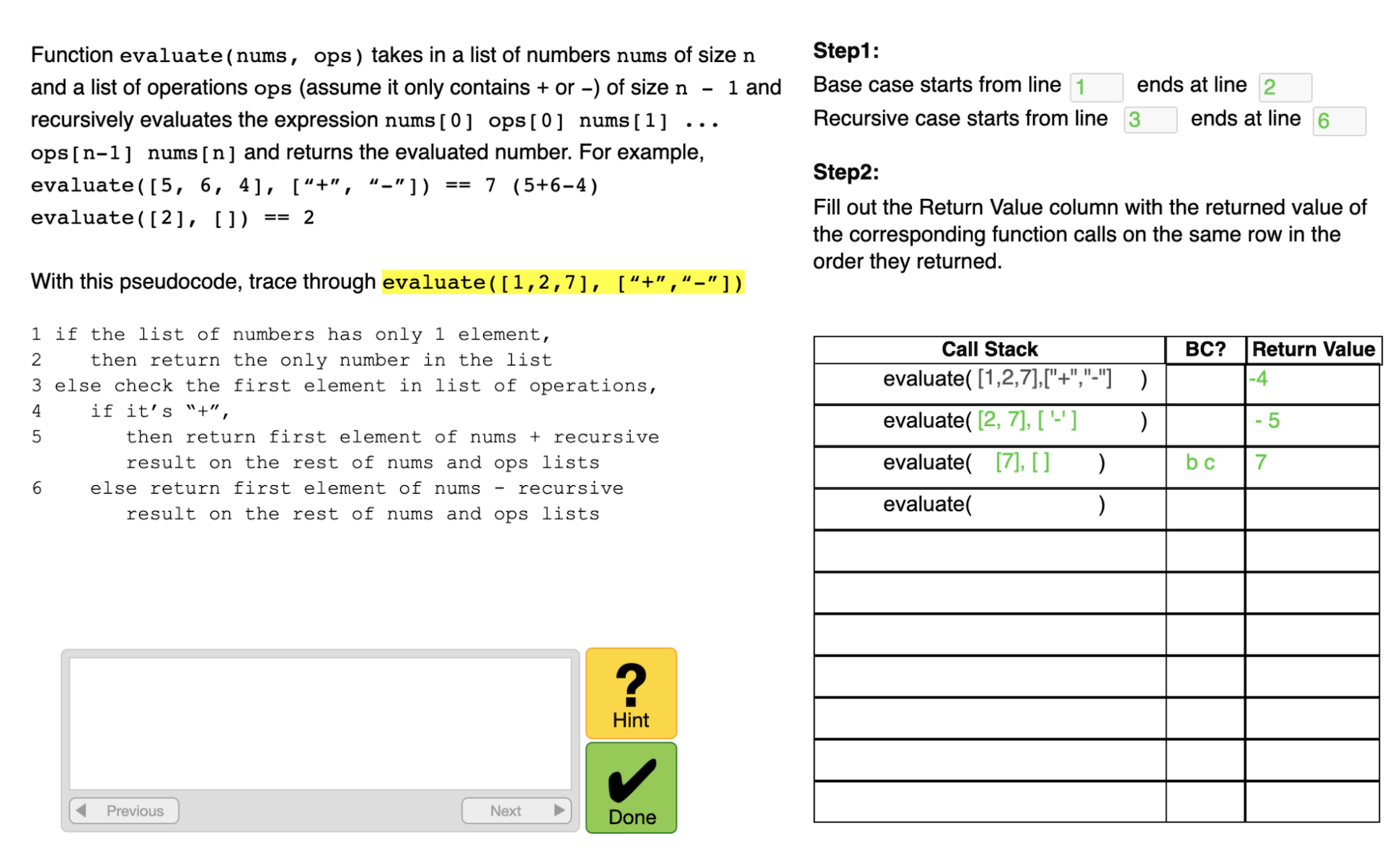 |
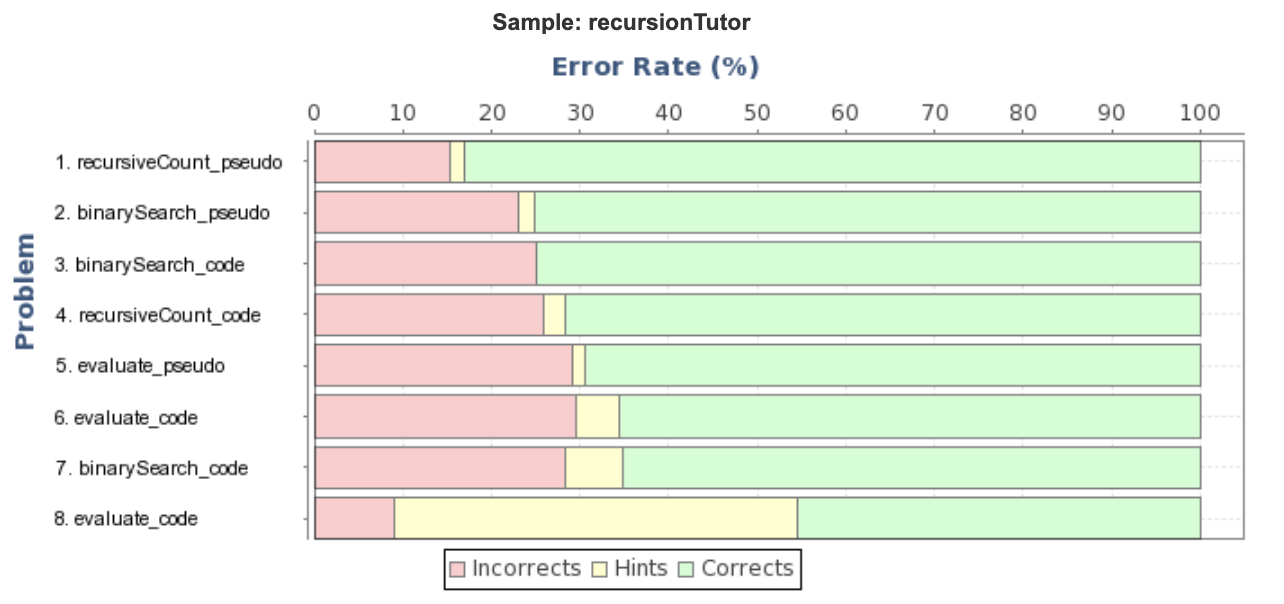
We tested our tutor prototype on 41 participants, collected log data, and performed some preliminary data analysis. The error rates are consistent with our hypothesis that code version is more difficult than the pseudocode version (involving an extra KC in understanding Python codes), and more complex data structure is harder to trace.
We also updated our tutor interface based on the feedback we received. To further improve our tutor, we can match KCs with skills at production rules level to present a skill bar on tutor interface that informs students of their progress, and enable more fine-grained data analytics to use techniques like learning factor analysis to improve the KC model2. We can also think about ways to mass produce recursion practice problems.
 |
We received positive feedback from students using our personalized tutor. They like the fact that our adaptive tutor
- presents the subgoal structure dynamically,
- provides step-wise feedback with immediate hints and bug messages,
- enforces the top-down order for input arguments in call stack column and bottom-up order for outputs in return value column, which illustrates the concept that recursive function peel off the original input to reach base case and start to return from base case call, and
- separates call stack, base case, and return value columns, which highlights the important components in recursive algorithms.
We also discover a lot of problems that our tutor didn’t address. For example, it’s hard to identify the types of error students make and provide more targeted hints. We specified KCs for “identifying the correct return value pattern” vs. “putting the correct values at corresponding rows”, as students may observe the return value pattern correctly but made an off-by-one error. As a TA it’s easy to tell what is the error that student make, but it’s really hard for cognitive tutor to distinguish the difference and provide specific feedback.
I like this project a lot as it’s quite interesting to apply the theories learned in class to real-world situation and see the strengths and limitations of adaptive technologies in CS education. As a course project, our tutor can only do so much, and the cognitive tutor authoring tool also has a steep learning curve (took us half a semester to learn). However, I still see a potential in making these adaptive technologies more accessible for educators and sharing the power of personalized education with more students.
-
Aleven, V., & Koedinger, K. R. (2013). Knowledge component approaches to learner modeling. In R. Sottilare, A. Graesser, X. Hu, & H. Holden (Eds.), Design recommendations for adaptive intelligent tutoring systems (Vol. I, Learner Modeling, pp. 165-182). Orlando, FL: US Army Research Laboratory. ↩
-
Koedinger, K. R., Stamper, J. C., McLaughlin, E. A., & Nixon, T. (2013). Using data-driven discovery of better student models to improve student learning. In H. C. Lane, K. Yacef, J. Mostow, & P. Pavlik (Eds.), Proceedings of the 16th international conference on artificial intelligence in education AIED 2013 (pp. 421-430). Berlin, Heidelberg: Springer. doi:10.1007/978-3-642-39112-5_43 ↩